★ AI Data 교육 안내 및 수강신청 사이트 - http://aidata.elancer.co.kr/student/edulist.php
교육 신청하기 | 2022 인공지능 학습용 데이터 라벨링 전문 교육
교육 신청하기 | 2022 인공지능 학습용 데이터 라벨링 전문 교육 | 교육과정 소개 및 수강신청 사이트입니다.
aidata.elancer.co.kr
[이전에 들은 교육 후기]
- 인공지능 윤리와 법(필수) : https://lbsdatastat.tistory.com/194
- 음성/텍스트(입문) : https://lbsdatastat.tistory.com/199
- 이미지/영상(입문) : https://lbsdatastat.tistory.com/201
- 이미지/영상(기본) : https://lbsdatastat.tistory.com/222
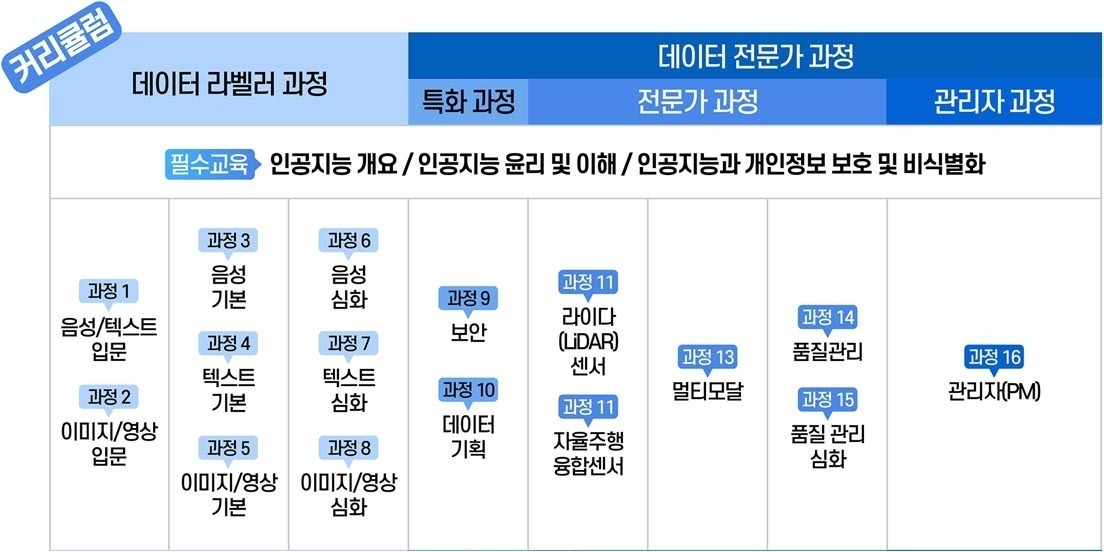
데이터 라벨러 교육에는 각 분야별로 입문, 기본, 심화 과정으로 세분화되어 있습니다. 기본 교육의 경우에는 실습 과제를 포함하여 강의를 수강해주셔야 합니다. 교안과 교재는 수강 사이트에서 다운로드받을 수 있으며, 해당 파일을 참고하여 교육에 참여하면 될 것으로 보입니다.
이번 음성 기본 과정은 약 95분 분량의 강의 5개를 수강하고, 실습과제를 제출해야 수료 처리가 됩니다. 강의의 경우 분량에 따라 최소 출석인정 요구시간을 채워주셔야 하고, 모든 강의의 최소시간을 채우게 되면 출석이 인정됩니다.
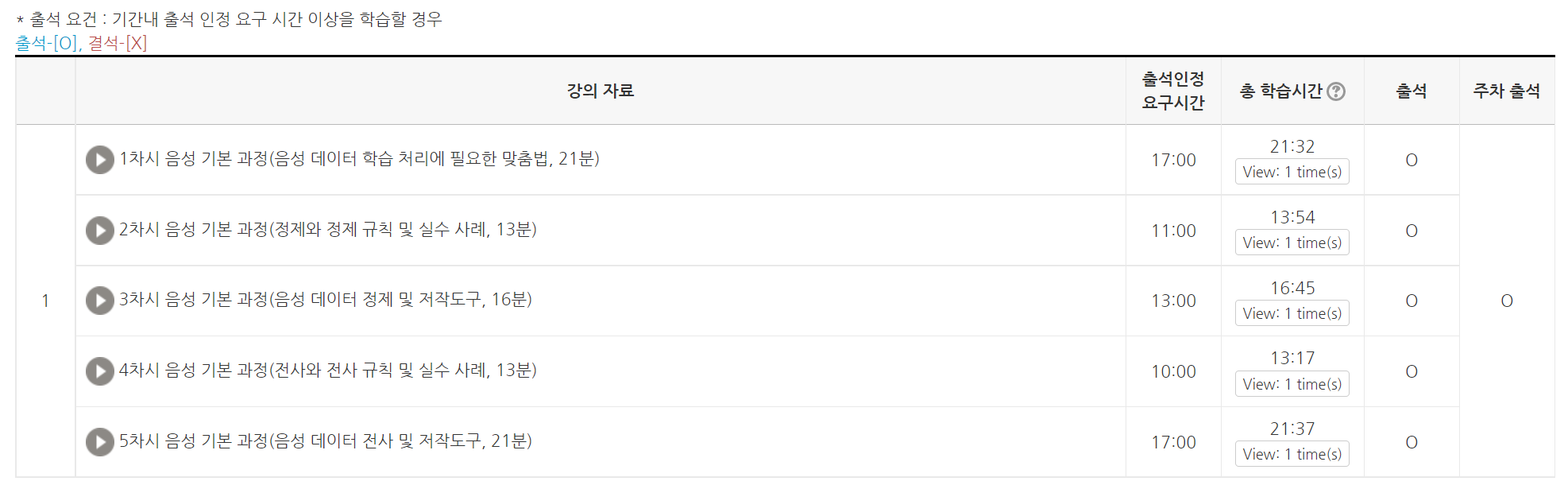
강의 순서는 이미지/영상(기본) 때와 다르게 맞춤법과 규칙 중심으로 이루어져 있습니다.
1차시의 경우 데이터 학습 처리에 필요한 "맞춤법"이라 해서, 자주 틀릴 수 있는 한국어에 대해 빠르게 알려주는 파트입니다. '국립국어원 표준국어대사전'을 기준으로 맞춤법을 맞춰서 작성해야 하므로, 라벨링하다가 맞춤법에 애로사항이 생길 경우 해당 사이트를 참고하면 좋겠습니다.
국립국어원 표준국어대사전
stdict.korean.go.kr
2차시는 정제와 정제 규칙에 대한 설명입니다. 음성 데이터 정제란 녹음된 데이터를 처음부터 끝까지 들어보며 잡음, 말 겹침, 소음, 긴 묵음 구간 등을 수정하거나 삭제하는 등 편집하는 작업을 뜻으로 전체적으로 제대로 녹음되었는지 확인되는 작업이라고도 합니다. 원시 데이터를 정제하여 전사 작업하기에 용이한 품질을 구축하는 과정이라 할 수 있습니다.
위와 같은 정제를 위해서는 배경 잡음, 말 겹침, 음성 공백을 삭제해야 하고 발화 사이에 공백이 너무 없다면 이를 추가해야 하기도 합니다. 여기서 대화는 최대한 자연스럽게, 정제가 안된다면 앞/뒤 문장을 활용해서 문장을 완성, 정제 후 문장이 자연스럽지 않다면 전체 삭제를, 재생 시간 손실을 최소화해야 하는 등 변수가 많다는 것을 유념해야 했습니다.
3차시는 정제 및 저작도구에 대한 소개였습니다. 음성 편집기라고도 하는 Audacity 프로그램에 대한 소개가 주를 이루는 챕터로서 정제 절차는 물론 단축키 소개, 저작도구를 통한 정제 방법에 대한 안내가 이루어진 파트였습니다. 실제 실습은 다른 방법으로 진행하였지만, 음성 데이터 라벨링이 필요하게 된다면 해당 프로그램을 활용해보는 것이 좋을 것으로 보였습니다.
Home
Welcome to Audacity Audacity® is free, open source, cross-platform audio software for multi-track recording and editing. Audacity is available for Windows®, Mac®, GNU/Linux® and other operating systems. Check our feature list, Wiki and Forum. Download
www.audacityteam.org
4차시는 전사와 전사 규칙입니다. 정제와 다르게, 사람이 말하는 소리를 글로 적어 문자화하는 작업으로, 청취만 가능한 음성 파일의 음성을 사람이 볼 수 있거나 인공지능이 학습할 수 있도록 문자화하는 작업이라고 할 수 있습니다. 맞춤법을 지키고, 발성한 대로 전사하고, 숫자/기호/특수문자/알파벳 등도 모두 소리나는 대로 한글로 해야 하는 등의 규칙을 배울 수 있었습니다.
마지막 5차시는 전사 및 저작 도구에 대한 소개였습니다. 마치 속기를 진행하는 것처럼 음성을 문자로 옮기는 작업이기 때문에, 문자화된 결과물이 중요하다고 안내가 되어 있습니다. 그래서인지 TranscriberAG와 같은 공개 소프트웨어나 디그랩의 데이터 팩토리 등에서 제공하는 웹 기반의 프로그램을 이용해 작업을 권장하셨습니다. 이번 과정에서의 실습도 전사를 진행했기 때문에, 위와 같은 프로그램을 통한 작업이 진행됐습니다.
TranscriberAG
What is TranscriberAG? The tool: TranscriberAG is designed for assisting the manual annotation of speech signals. It provides a user-friendly graphical user interface (GUI) for segmenting long duration speech recordings, transcribing them, labeling speech
transag.sourceforge.net

이번 실습은 위에서 언급한 웹 프로그램을 통한 음성 데이터 전사로 안내되었습니다. 연습 파일 3개(음성/답안)씩, 그리고 테스트 음성 파일 하나가 제공되었는데요, 연습 파일을 활용해서 웹 전사툴(AI Data Factory_ddfplus.co.kr)을 통해 연습해보고 테스트 음성을 전사하여 제출하면 되는 과정이었습니다.
데이터 팩토리
세계 최초 인공지능속기 개발, AI속기키보드, 속기사교육, 국가자격 합격1위
ddfplus.co.kr

그래서 실습을 진행하게 되면, 위와 같은 형태와 같이 음성 데이터를 전사하게 됩니다. 테스트 파일은 5분 정도로 구성되어 있으며, 소리 나는 대로 한글만을 사용해서 잘 받아적는 것이 중요한 포인트라고 생각했습니다. 그래서인지 타자가 빠를수록, 다른 소리의 방해 없이 작업할 수 있는 환경인 분들에게 유리한 과정이라고 느껴졌습니다.
WAV 음성 파일을 불러오고, 파일저장 버튼을 누르면 JSON 파일과 TXT 파일이 동시에 저장됩니다. 만약 하나만 저장될 경우 동시 저장을 허용해주시고, 저장한 자막 파일을 불러오고 싶다면 JSON 파일을 불러와야 한다는 점을 주의해 주시면 되겠습니다.
참고로, 일시 정지 단축키가 Esc, 몇 초 뒤로 스킵하는 단축키가 F1이라는 점도 익숙해지면 훨씬 편해집니다.

저같은 경우에는 하루 동안 기다려서, 실습 결과물이 채점되면서 위와 같은 피드백을 받게 되었습니다. 화자 구분 누락, 맞춤법보다 들리는 그대로 작성하기, 한두 글자씩 누락된 부분 확인 등 완전하진 않았지만 그래도 전사 과정에서 치명적인 문제가 발생하진 않았어서 높은 점수를 받을 수 있었습니다.
만약 이번 과정에서 실습을 진행하게 된다면, 직접 수기로 채점하기 때문에 제출 즉시 결과가 나오지는 않다는 점을 주의해 주시면 좋겠습니다.

다섯 번째 과정을 수료했습니다. 원래 생각했던 것보다 많은 교육을 듣고 있어서 그런지, 슬슬 라벨링 과정 자체가 익숙해지는 느낌이 들기도 하네요. 우선 남은 기본 레벨인 '텍스트' 과정과, 데이터 전문가 특화 과정인 '보안'과 '데이터 기획'까지 9월 내에 모두 수료하는 목표는 아직 그대로입니다. 데이터를 실제로 다뤄보는 측면에서 메리트를 얻고 있는 만큼, 앞으로 더욱 다양한 데이터를 다룰 때 보다 빠르게 적응할 수 있을 것이라 기대하고 있습니다.
'데이터 [Data] > 라벨링 (Labeling)' 카테고리의 다른 글
| 라벨링교육 데이터기획 수강 후기 [2022년 인공지능 학습용 데이터 라벨링 전문 교육] (0) | 2022.09.14 |
|---|---|
| 라벨링교육 텍스트(기본) 수강 후기 [2022년 인공지능 학습용 데이터 라벨링 전문 교육] (0) | 2022.09.09 |
| 라벨링교육 이미지/영상(기본) 수강 후기 [2022년 인공지능 학습용 데이터 라벨링 전문 교육] (0) | 2022.08.12 |
| 라벨링교육 이미지/영상(입문) 수강 후기 [2022년 인공지능 학습용 데이터 라벨링 전문 교육] (0) | 2022.07.15 |
| 라벨링교육 음성/텍스트(입문) 수강 후기 [2022년 인공지능 학습용 데이터 라벨링 전문 교육] (0) | 2022.07.13 |




댓글