자료출처: MS SQL 기반 데이터베이스 배움터 (생능출판사) http://www.yes24.com/Product/Goods/7489842
데이터베이스 배움터 - YES24
이론과 실무가 조화된 최적의 데이터베이스 책데이터베이스를 제대로 활용하는 데 반드시 필요한 데이터베이스의 기본적인 개념 및 이론을 이해하기 쉽게 설명한 책이다. 이와 함께 활용 기술
www.yes24.com



위 테이블을 통해서 SELECT문을 정리하고자 한다. SQL에서 SELECT문은 굉장히 다양하게 활용할 수 있다. 애트리뷰트를 모두 또는 일부만 검색할 수도 있고, 상이한 값들을 검색할 수도 있고, 특정 투플들을 검색할 수도 있고, 문자열을 비교할 수도 있고, 검색 조건을 만들 수도 있는 등의 다양한 검색 기능을 수행할 수 있다. 그 외에도 정렬, 집단 함수, 그룹화, 집합 연산 등과 같이 여러 가지 기능을 수행할 수 있다.
우선 SELECT문의 기본 형식이다. SELECT문은 SELECT-FROM-WHERE절로 이루어진 구문이며, 이러한 기본적인 SELECT문을 SELECT-FROM-WHERE 블록이라고 부른다. 아래 구문에서 ‘[]’ 안에 들어있는 것은 선택 사항을 뜻하고, ‘|’ 기호는 “또는(OR)”을 의미한다.

위처럼 SELECT절과 FROM절만 필수적인 절이고, 나머지 절들은 선택사항으로 사용된다. SELECT절 옆의 DISTINCT절은 중복 여부를 검사하여 중복을 제거할 때 사용되고, GROUP BY 절은 여러 개의 애트리뷰트를 하나의 그룹으로 묶는 역할을 할 때 사용되고, HAVING절은 그룹화된 애트리뷰트들과 같은 투플들의 그룹에 대한 조건을 나타낸다. ORDER BY절은 애트리뷰트들을 정렬하는 기능을 수행하는데 ASC 옵션으로 오름차순 정렬을, DESC 옵션으로 내림차순 정렬을 나타낸다.

1) 릴레이션의 모든 애트리뷰트나 일부 애트리뷰트들을 검색
: SELECT문을 통해서 전체 부서의 모든 애트리뷰트를 검색하는 질의도 수행하고, 모든 부서의 부서번호와 부서이름만 출력하는 질의도 수행할 수 있다. SELECT 절에서 리스트 대신에 *를 사용하면 릴레이션에 속하는 모든 애트리뷰트를 검색하게 된다. 릴레이션이 큰 경우 검색 시간이 증가할 수 있으므로 모든 애트리뷰트를 찾아야 하는 경우가 아닌 이상 *를 사용하는 것을 권장하지는 않는다. 일부 애트리뷰트만 검색하기 위해서는 애트리뷰트의 리스트를 SELECT 절에 입력한다.

2) 상이한 값들을 검색
: SELECT문의 결과에는 중복된 투플들이 디폴트로 존재할 수 있다. 이 때, DISTINCT절을 사용해서 명시적으로 요청했을 때에 한해 중복을 제거하게 된다. DISTINCT절을 명시하면 투플들이 정렬하여 중복 여부를 검사하고, 중복된 투플들이 존재하면 이를 제거한 후 사용자에게 결과를 제시하게 되는 원리이다. 모든 사원들의 직급을 검색하라는 질의와, 모든 사원들의 ‘상이한’ 직급을 검색하라는 질의의 차이는 다음과 같이 나타나게 된다.

3) 특정 투플들의 검색
: 이는 WHERE 절을 활용하여 명시할 수 있다. 여섯 개의 비교 연산자(=, <, <=, >, >=, <>)를 사용하여 애트리뷰트와 애트리뷰트 또는 애트리뷰트와 상수를 비교할 수 있다. 이 때, 숫자가 아닌 문자와 같은 상수들은 단일 인용기호(‘’)로 에워싸야 한다. “2번 부서에 근무하는 사원들에 관한 모든 정보를 검색하라”는 예제 질의에서는 모든 정보를 검색하기 때문에 SELECT *, 2번 부서에 근무하는 사원들에 관한 정보이므로 FROM EMPLOYEE에 WHERE DNO = 2라는 구문이 추가된다. 이를 한 구문으로 합치면 SELECT * FROM EMPLOYEE WHERE DNO = 2; 라는 구문이 완성된다.

4) 문자열 비교
: LIKE 비교 연산자는 문자열의 일부에 대해서 비교 조건을 명시한다. 이 때 wild 문자 ‘%’는 0개 이상의 문자열과 대치되고, wild 문자 ‘_’는 임의의 한 개의 문자와 대치된다. 예를 들어 LIKE ‘S%’는 첫 문자가 S이고 그 다음에는 0개 이상 임의의 문자열이 올 수 있고, LIKE ‘S___’는 첫 문자가 S이고 그 다음에는 정확히 3개의 문자가 올 수 있는 방식이다. 이는 뒷부분, 앞부분, 중간부분 어디든 사용할 수 있다. 다만, wild 문자가 문자열의 앞부분에 사용되면 조건에 맞는 투플들을 검색하기 위해서 인덱스를 사용하지 못하며, 모든 투플들을 하나씩 읽어야 하기 때문에 수행 시간이 오래 걸릴 수 있다. 다음 예제는 “이씨 성을 가진 사원들의 이름, 직급, 부서번호를 검색하라”는 질의에 대한 결과이다.

5) 다수의 검색 조건
: WHERE 절에 여러 조건들이 논리 연산자로 결합될 수 있다. 그러나 단일 값을 갖는 투플을 AND로 묶을 경우, WHERE절을 만족하는 투플은 하나도 없다. 즉, 결과 릴레이션이 빈 릴레이션이 나올 수도 있는 것이다. WHERE절에 AND, OR, NOT을 사용하여 여러 조건들로 이루어진 식을 표현한다. 우선순위는 비교 연산자 -> NOT -> AND -> OR 순이다. 다음 예제는 “직급이 과장이면서 1번 부서에서 근무하는 사원들의 이름과 급여를 검색하라”는 질의에 대한 결과이다.
6) 부정 검색 조건
: 사용자가 원하지 않는 투플들을 배제하기 위해서 부정 연산자 <>를 사용하기도 한다. 아래 예제는 “직급이 과장이면서 1번 부서에 속하지 않은 사원들의 이름과 급여를 검색하라”는 질의에 대한 결과이다.

7) 범위를 사용한 검색
: 원하는 투플들의 조건을 명시하기 위해서 WHERE절에 범위를 나타내는 연산자 BETWEEN을 사용할 수 있다. BETWEEN을 사용하여 WHERE절을 좀 더 읽기 쉽게 만들 수 있으며, 비교 연산자를 사용해도 동일한 결과를 만들 수 있다. 아래 예제는 “급여가 3000000원 이상이고, 4500000원 이하인 사원들의 이름, 직급, 급여를 검색하라”는 질의에 대한 결과이다. BETWEEN은 양쪽의 경곗값을 포함하므로, 비교 연산자의 이상/이하(>=, <=)와 동일하다.
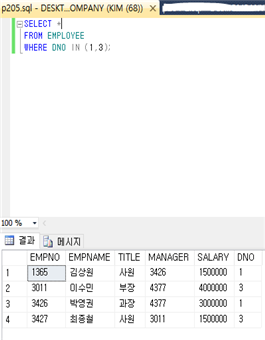
8) 리스트를 사용한 검색
: 리스트 내의 값과 비교하는 IN 연산자가 있다. ‘WHERE DNO IN (1, 3)’는 DNO의 값이 1이나 3에 속하는가를 검사한다. IN의 부정으로 사용하려 하면 NOT IN을 사용하면 되고, IN을 사용하면 다수의 OR을 사용할 필요 없이 OR와 동일한 결과를 확인할 수 있다. 아래 예제는 “1번 부서나 3번 부서에 소속된 사원들에 관한 모든 정보를 검색하라”는 질의에 대한 결과이다.

9) SELECT절에서 산술 연산자(+, =, *, /) 사용
: SELECT절에 산술 연산자를 사용하여 수식을 표현해도 실제로 데이터베이스 내의 값이 변경되지는 않는다. 이 점을 활용하여 데이터베이스 내의 값이 어떻게 바뀔 것인가 파악하기 위한 목적으로도 사용한다. 다음 예제는 “직급이 과장인 사원들에 대하여 이름, 현재 급여, 급여가 10% 인상되었을 때(NewSalary)의 값을 검색하라”는 질의에 대한 결과이다.
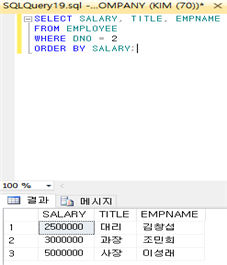
10) ORDER BY절
: 질의 결과를 오름차순이나 내림차순으로 정렬하는 경우가 있다. 정렬을 위해 ORDER BY절에서 하나 이상의 애트리뷰트를 사용하여 검색 결과를 정렬할 수 있다. 디폴트 정렬 순서는 오름차순(ASC)이며, DESC를 지정하여 정렬 순서를 내림차순으로 지정할 수 있다. NULL값도 정렬 결과에 포함되는데, 오름차순에서는 가장 마지막에, 내림차순에서는 가장 처음에 나타난다. 아래 예제는 “2번 부서에 근무하는 사원들의 급여, 직급, 이름을 검색하여 급여의 오름차순으로 정렬하라”는 질의에 대한 결과이다.

11) 집단 함수
: 집단 함수란 데이터베이스에서 검색된 열 투플들의 집단에 적용되는 함수이다. 각 집단 함수는 할 릴레이션의 한 개의 애트리뷰트에 적용되어 단일 값을 반환한다. 집단 함수는 SELECT절과 HAVING절에만 명시할 수 있다. 집단 함수에는 개수를 세는 COUNT, 값들의 합을 나타내는 SUM, 평균 AVG, 최댓값 MAX, 최솟값 MIN 등이 있다. COUNT와 MIN, MAX는 숫자형 애트리뷰트와 비 숫자형 애트리뷰트 모두에 적용할 수 있지만, SUM과 AVG는 숫자형 애트리뷰트에만 적용할 수 있다. COUNT(*)를 제외한 모든 함수들은 NULL값을 제거한 후 남아있는 값들에 대하여 값을 구한다. 다음 예제는 “모든 사원들의 평균 급여와 최대 급여를 검색하라”는 질의에 대한 결과이다.

12) 그룹화
: GROUP BY절에 사용된 애트리뷰트에 동일한 값을 갖는 투플들이 각각 하나의 그룹으로 묶인다. 이 절에 사용되는 애트리뷰트는 집단 함수에 사용되지 않는 애트리뷰트여야 하고, 각 그룹에 대하여 결과 릴레이션에 하나의 투플이 생성된다. 따라서 SELECT절에는 각 그룹마다 하나의 값을 갖는 애트리뷰트, 집단 함수, 그룹화에 사용된 애트리뷰트들만 나타날 수 있다. 아래 예제는 “모든 사원들에 대해서 사원들이 속한 부서번호별로 그룹화하고, 각 부서마다 부서번호, 평균급여, 최대급여를 검색하라”는 질의에 대한 결과이다.

13) HAVING
: 때로는 어떤 조건을 만족하는 그룹들에 대해서만 집단 함수를 적용할 수 있는데, 각 그룹마다 하나의 값을 갖는 애트리뷰트를 사용하여 각 그룹이 만족해야 하는 조건을 명시한다. WHERE절과 비슷한 역할을 하지만 WHERE절은 투플들을 걸러내고, HAVING은 그룹들을 걸러내는 기능을 수행한다. 다음 예제는 “모든 사원들에 대해서 사원들이 속한 부서번호별로 그룹화하고, 평균 급여가 2500000원 이상인 부서에 대해서 부서번호, 평균급여, 최대급여를 검색하라”는 질의에 대한 결과이다. DNO에 대해서 GROUP BY를 먼저 수행하고, 그룹에 대한 조건에 맞는 투플들만 검색하는 기능을 수행한다.
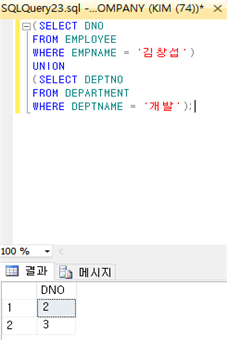
14) 집합 연산
: 집합 연산을 적용하려면 두 릴레이션이 합집합(UNION ALL) 호환성을 가져야 한다. 첫 번째 질의의 애트리뷰트 이름들이 결과에 나타나는데, UNION ALL을 제외하고 결과가 오름차순으로 정렬된다. UNION ALL을 제외한 모든 집합 연산의 결과 릴레이션에서 중복된 투플들이 자동적으로 삭제된다. 다음 예제는 “김창섭이 속한 부서이거나 개발 부서의 부서번호를 검색하라”는 질의에 대한 결과이다.
'데이터 [Data] > 데이터베이스론' 카테고리의 다른 글
| 데이터베이스론 보고서 9 : 2진 관계 타입을 릴레이션으로 변환하는 형태 (0) | 2021.07.16 |
|---|---|
| 데이터베이스론 보고서 8 : “관계 <-> 외래 키”라는 항목 (0) | 2021.07.15 |
| 데이터베이스론 보고서 6 : ER 모델이 개선된 것 + 각 특징 (0) | 2021.07.13 |
| 데이터베이스론 보고서 5 : Join을 할 때 사용되는 제약조건 (0) | 2021.07.12 |
| 데이터베이스론 보고서 4 : 데이터 마이닝 (0) | 2021.07.11 |




댓글